Deep Learning for Language Modeling课程地址:点击查看
Language Modeling
Introduction
- 语言模型的实质就是估计一个句子产生的概率。换言之,就是估计一个词语序列出现的概率
- 对于一个词语序列:W1,W2,W3,…,Wn
- 估计概率P(W1,W2,W3,…,Wn)
- 语言模型的应用举例:
- 语音识别
- 不同的句子可能有相同的读音,使用语言模型就可以计算出这些具有相同读音的句子各自产生的概率,从而舍弃那些概率低的句子,返回产生概率高的句子。
- 句子生成
- 可以生成一些符合语义和语法的句子,作为人机交互的接口
- 语音识别
- 实现方法
- N-gram
- 深度神经网络
N-gram
对于如何估计一个词语序列的产生概率,在过去一个很长的时间内都采用了N-gram的方法,这个方法的利用了词语之间的依赖性,通过统计大量的文本数据来获取一个词语的条件概率,最终通过这些条件概率来获得一个句子的产生概率。比如我们要计算“wreck a nice beach”的产生概率,在2-gram的情况下,我们会计算各个单词的条件概率P(wreck|START)、P(a|wreck)…最终将这些条件概率相乘就得到了整个句子的产生概率。而这些条件概率则是通过统计得到的:P(beach|nice) = count(nice beach)/ count(nice)。3-gram和4-gram的情况类似。但是这种方法有一个缺点,即我们要计算的句子中经常会出现未登录词,或者未登录的组合,这样的话,即使这个句子本身是有意义的,产生也会被估计为0。
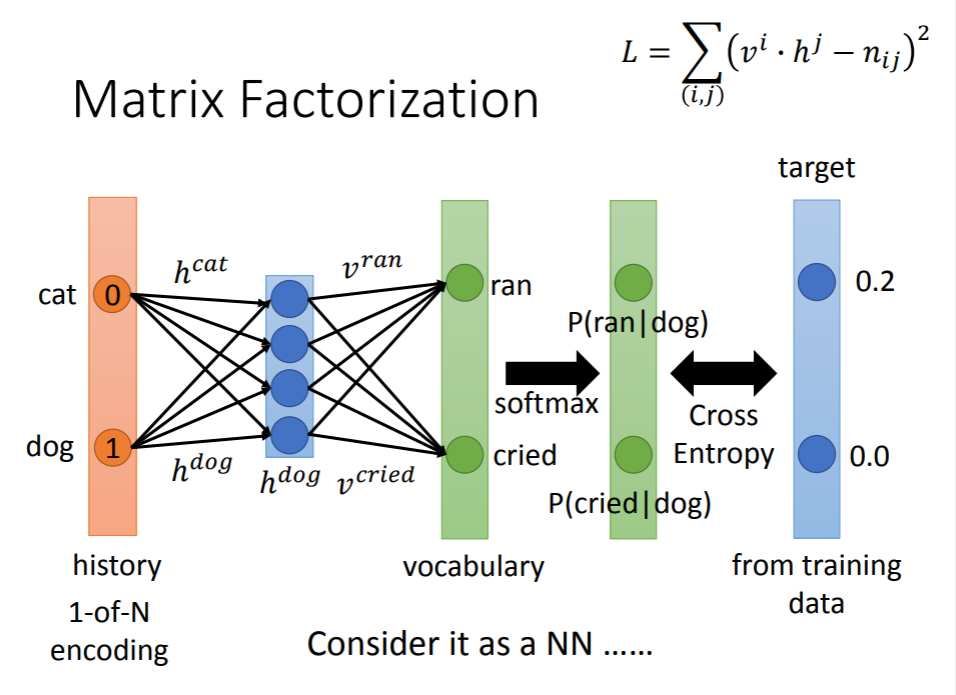
为了解决上述问题,相关人员借鉴了推荐系统的算法,在对文本数据进行统计之后,我们得到了一个history-vocabulary矩阵,矩阵中的元素即为2-gram里的条件概率。
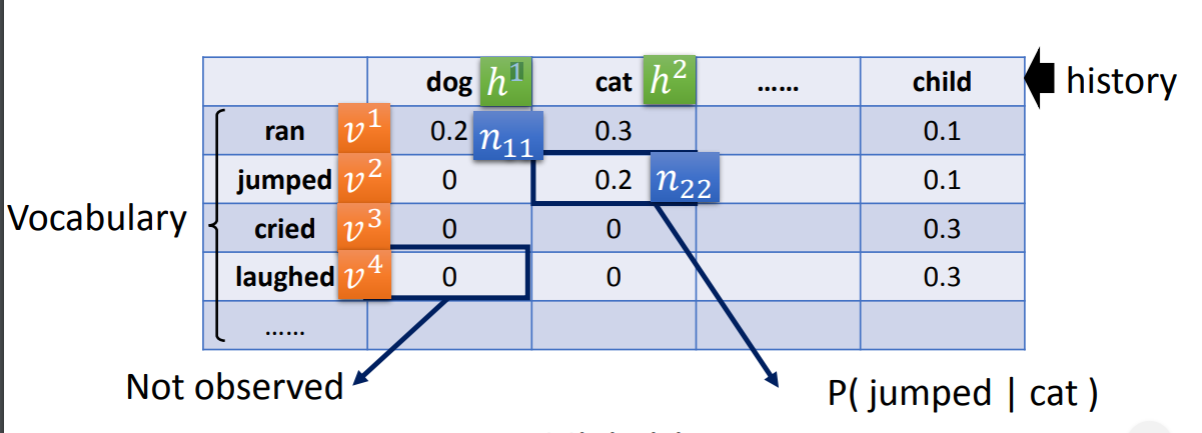
矩阵里的每个history和vocabulary对应的Vi和Hi都是一个个向量,是我们要通过这些概率学习得到的,那么如何学习得到这些向量呢?一方面可以使用奇异值分解的方法,但好像效果不太好,另一方面可以使用梯度下降法,在这个方法下,我们希望Vi·Hj得到的scalar和Nij的值越接近越好,我们定义一个error函数:
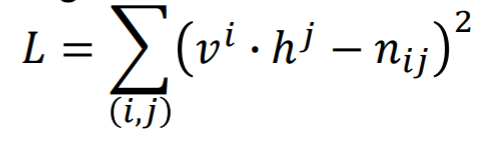
在这个矩阵中,Vi和Hi都是randomly initialized,之后求得error对每个矩阵中的每个元素的梯度,并进行迭代,最终得到收敛的向量。而且对于相似的词语他们对应的向量也比较相似,比如“猫”和“狗”对应的向量就很类似。那么在计算一个句子的产生概率时就使用向量之间的点乘结果来作为相应的条件概率,这样,对于未登录组合也不会产生概率为0的结果,而且对于相似的组合也能产生相似的概率,比如“一只猫在跑”和“一只狗在跳”。我们认为在这样一个Matrix Factorization的过程中,自动完成了smoothing这个步骤。
NN-based Language Modeling
在N-gram模型中,我们计算一个句子的产生概率是通过计算各个条件概率的乘积来得到的,NN-based LM也类似,不同之处在于我们现在不通过统计手段来获得条件概率,我们使用神经网络来获得条件概率。我们将一个词语输入进神经网络,输出则是一个向量,向量的维度是vocabulary_size,每个元素的值都是某一个词语作为下一个词语的概率,如下所示:
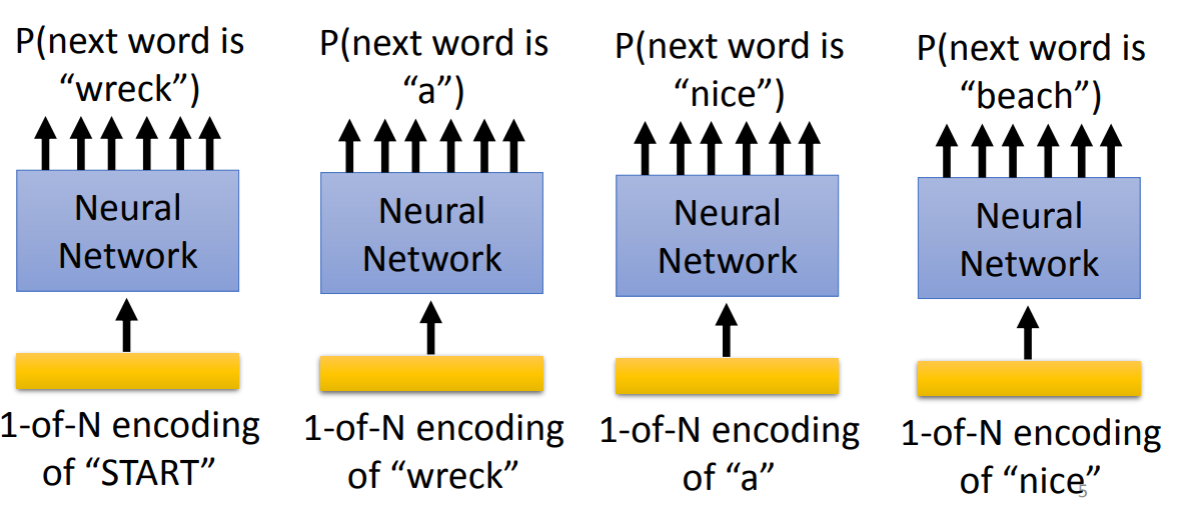
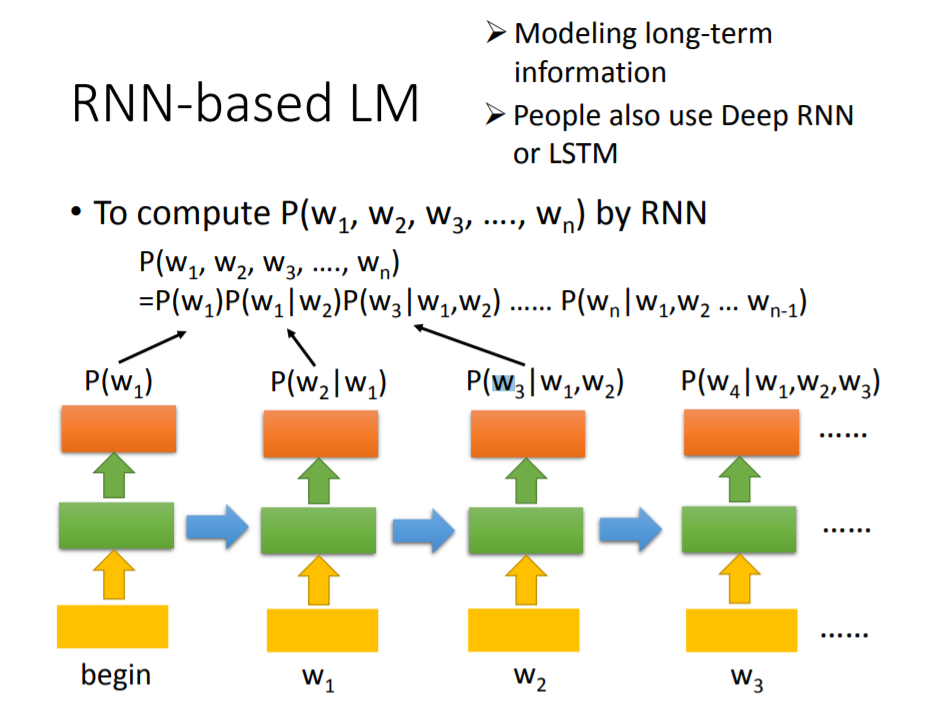
我们还可以使用RNN来进行LM,在这个模型中,我们的每个输出都依赖于之前所有的输入,因此输出的结果也会更加合理。
Matrix Factorization 和 NN的类似之处
我们可以将Matrix Factorization看作一种简化的NN-based LM,在这个LM中,输入的是one-hot vector,通过一个[vocabulary_size,dim]的系数矩阵我们得到隐层数据Hi,之后将隐层数据和另一个系数矩阵相乘(该系数矩阵的元素是Matrix Factorization中的vocabulary的向量)即可得到一个输出向量,维度为vocabulary_size,其中每个元素都是对应单词的概率。