
Tensorflow中的实现:点击查看
Abstract
- 提出了一种基于
BI-LSTM的序列标记模型。 - 由于使用了
Bidirectional LSTM,使得模型能够充分利用序列的前后信息。 - 由于使用了
CRF层,可以利用句子层级的标记信息。
1、Introduction
- Sequence tagging主要包括以下几个任务:
- POS
- chunking
- NER
- 现有序列标注模型大都基于以下几种线性统计模型
- HMM(Hidden Markov Models)
- MEMMs(maximum entropy Markov models)
- CRF
- Convolutional based models
- 该论文主要做了以下几点工作:
- 系统地比较了几种tagging模型的performance。
- 首次将
Bidirectional LSTM以及CRF引入tagging领域。 - 证明了
BI-LSTM模型具有更强的鲁棒性和依赖性。
3、Models
该篇论文论述了多个模型,包括:LSTM、BI-LSTM、CRF、LSTM-CRF networks、BI-LSTM CRF networks。当使用LSTM和BI-LSTM时,直接将LSTM在每个时间片刻的输出经过一个分类器得到该词对应的tag。
- CRF networks
在预测当前标签时,有两种利用相邻标签的方法:- 在每个time-step预测标签时,给出一个tags的分布,接着利用beam-like decoding方法找出最佳的 tag 序列。最大熵分类器和最大熵马尔科夫模型即属于此类。
- 聚焦于句子层级而非单个词的position,这种方法通常使用CRF模型。
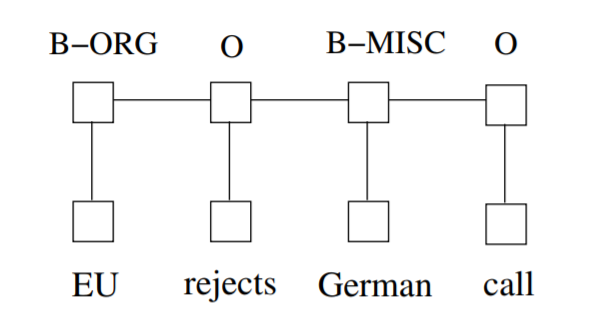 CRF模型
CRF模型
可以证明CRFs在tagging任务中可以产生更高的准确率。
- LSTM-CRF networks
该模型通过LSTM来充分获得一个句子过去的信息,通过CRF来利用整个句子的tag信息。CRF层可表示为一个连接了LSTM output的一条直线。CRF层有一个状态转移矩阵。使用CRF层,我们能充分利用一个句子过去和未来的tags来判断一个正确的tag,这和通过BI-LSTM来获取句子完整信息类似。通过将句子输入该模型,我们得到一个输出矩阵f-theta,矩阵中的每一个元素代表一个单词被标记为一个tag的分值。而通过CRF我们可以得到一个状态转移矩阵A,A-ij表示第i个tag转移到第j个tag的分值。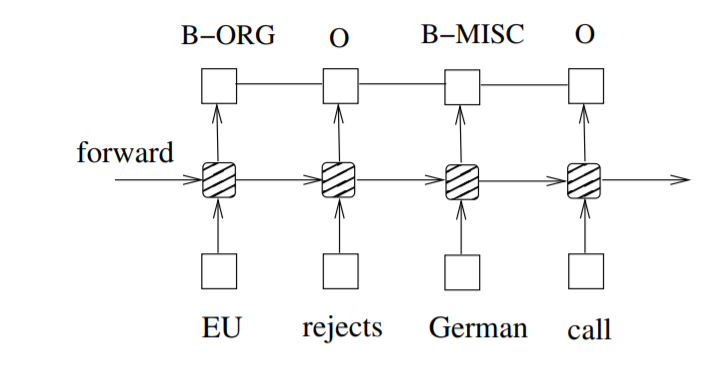
LSTM-CRF模型
因此整个模型的参数变为 theta(new) = theta(LSTM) + A。给定一个句子X和一个对应的tag路径i,评价该tag序列的方法为:
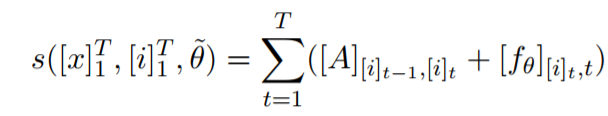
tag序列评价公式 - BI-LSTM-CRF networks
与LSTM-CRF模型类似,只是使用了BI-LSTM来替代LSTM。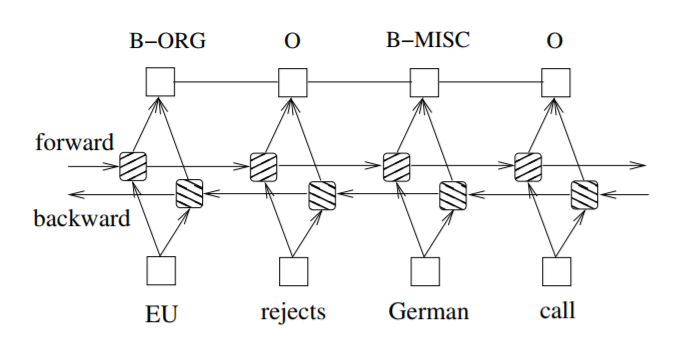
BI-LSTM-CRF 模型
4、Training procedure
使用SGD算法来实现参数更新。对整个训练数据进行多轮训练,每轮训练时输入的是一个batch。每次输入训练数据时,首先运行BI-LSTM模块,得到f-theta矩阵。接着运行CRF层得到状态转移矩阵。最后使用BP算法来更新整个模型的参数。

Bidirectional LSTM CRF model training procedure
