Tensorflow中的实现:点击查看
1、概述
- 使用带
Attention机制的LSTM来对文章进行自动摘要。 - 使用encoder对文章进行编码,decoder产生summarization。
- 使用了一种混合评价机制——用户评价及系统评价。
2、引言及现状
- 现有两种摘要方法:extractive和abstractive
- extractive:从原文中抽取相关段落作为摘要。
- abstractive:模型根据语义对原文进行改写与总结。
- 文章headlines通常是新闻首段的概要,论文利用了这种直觉,在训练时只使用首段作为训练数据。
- 在文章中,作者着重关心以下几个问题:
encoder-decoder模型在文章摘要领域的表现是否优于现有模型。- Amazon的
AWS是否可以满足LSTM在训练过程中对内存以及计算能力的要求。 Tensorflow+AWS这种组合架构能在何种程度上帮助我们实现一个这种模型?encoder-decoder架构在文摘这一任务上的表现如何?- 模型能否通过
Turing test?
3、相关工作
3.1、前人工作
Lopyrev使用encoder-decoder以及attention机制产生标题,首先会对模型输入训练数据,每个时间片段输入的数据都是一个word(分布式表示),之后词向量会输入一个多层RNN中,待将所有单词输入RNN之后,得到隐层状态h。接下来是decoder阶段,首先一个结束标记输入decoder,词嵌入层将符号转换为分布式表示。通过encoder-decoder和attention机制,decoder逐个产生标题单词直到一个结束标志。在每生成一个单词之后,生成的单词会作为下一个时间片段的输入。最后一步称为“teacher forcing”:expected word会被输入至decoder中。
3.2、评价方法
主流上,有两种评价方法:intrinsic和extrinsic。
- 大部分模型采用intrinsic,这种评价方法让自然人来评价摘要质量。4个最常用的评价指标分别是:
- 准确率
- 召回率
- F值
- Rouge:生成摘要和原标题之间重叠的信息量。
Summary informativeness是另一个重要的指标,它是指生成标题对原文的信息保有程度。
- 另一方面,extrinsic则关注于生成标题的efficiency和acceptability以及生成标题在解决任务时的表现。比如,task-based评价会关注于生成文摘在回答与原文有关的问题这一任务时的表现。
在本论文中,使用人工评价生成文摘的一致性、informativeness以及生成文摘和原文摘之间的相似性。
方法论
4.1、数据集
English Gigaword 2nd edition dataset
4.2、数据预处理
通过一系列首段产生两个list:一个用来存储headlines,另一个用来存储文章首段sentences,最终得到1344565个headline-sentence pair。
4.3、词长度箱
我们希望在为长度为50-60词的文章生成标题时,使用的是从类似长度文章中学习得出的知识,因此我们通过统计首段的长度,将预处理后的数据分成不同的bucket。
4.4、Encoder-decoder LSTM模型
Encoder-decoder模型是一种seq2seq模型。与之前的工作相比,该论文主要有两点不同。第一,该论文使用了5个buckets,先前的模型则使用了已给bucket,因此会对sentence进行比较少的padding。第二,该论文使用了一种greedy decoder而非beam search decoder。
一个带Attention机制的LSTM模型如下图所示:
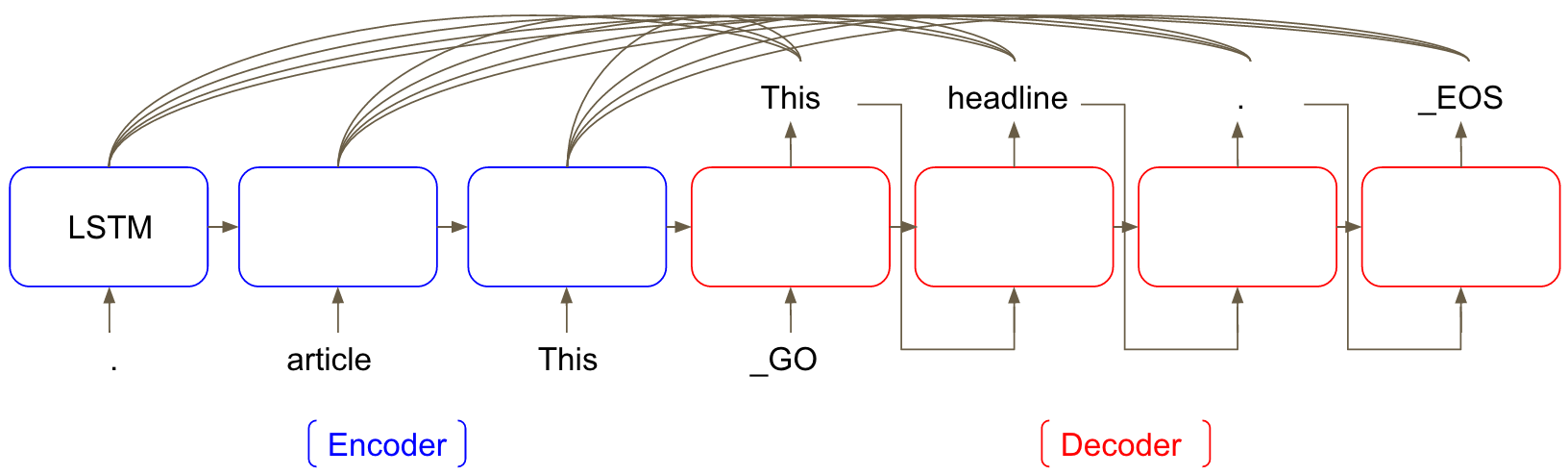
模型具有两个部分,第一部分是LSTM encoder,该部分对输入数据进行编码,第二部分是decoder,用于产生标题。在输入文章sentence时,使用倒序输入,因此,在产生标题时,原文中的头几个单词距离标题中的头几个单词更近,可以捕获短途依赖。倒序输入已经在机器翻译中被证明表现不俗。在产生标题的过程中,每个时间段生成的单词会被视作下一个时间段的输入,而attention机制则同时对encoder和decoder的隐层状态进行加权求和。
该文章使用tensorflow来完成带attention机制的seq2seq模型的构建,encoder与decoder的RNN均为3层,hidden units的个数均为512个,embedding维度也为512,dropout rate为0.2.除此之外,该论文4.3的统计结果设计了5个bucket((30,10),(30,20),(40,10),(40,20),(50,20))(即5个不同的encoder-decoder模型)。bucket(a,b)中,a指文章长度,b指标题长度。
5、结果
- 原始数据集分割:70%training、20%evaluation、10%testing
- 超参数:{batch_size:128, learning_rate:0.5, decay_factor:0.99, epochs:10}
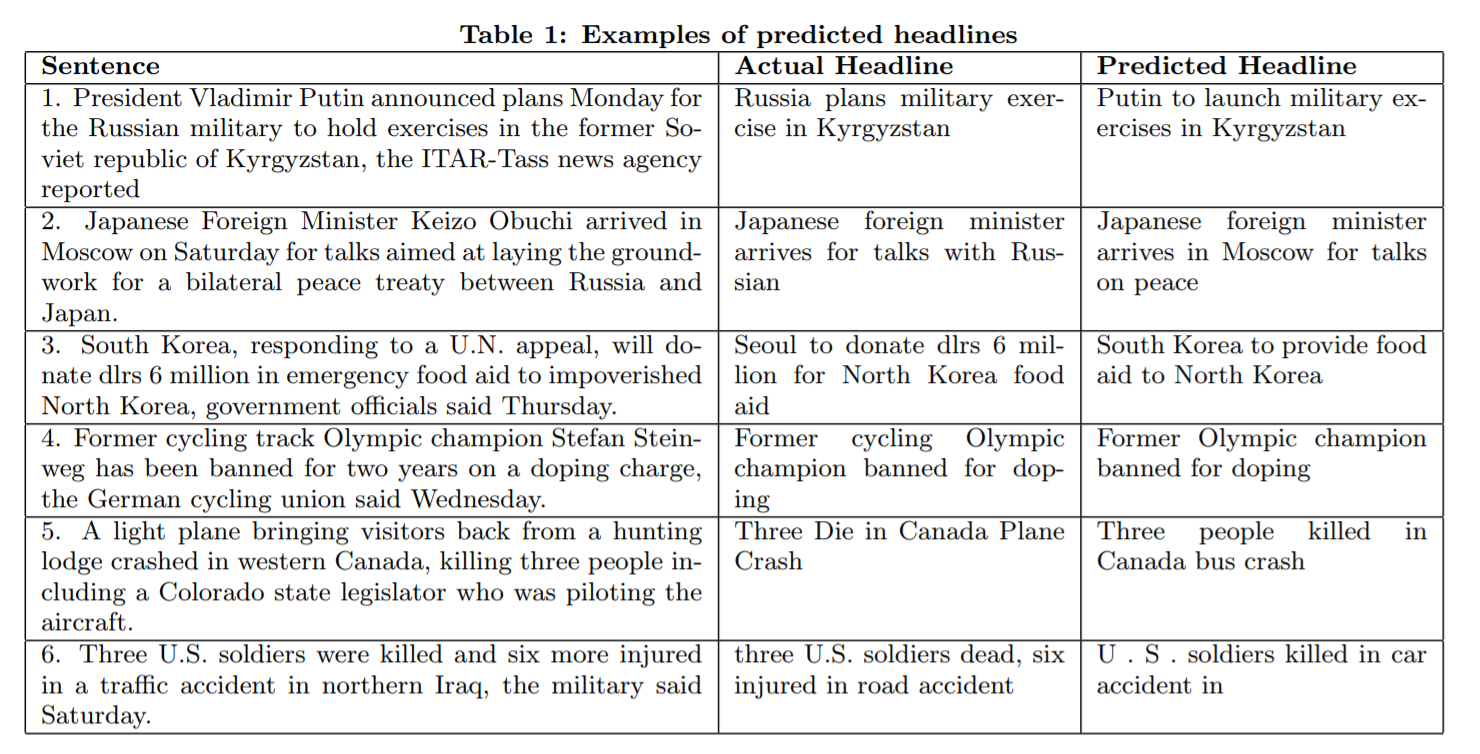
论文从testing data中选取了3个good prediction和3个 bad prediction。在bad prediction中,模型会丢失重要信息如“cycling”,或者加入原文中不存在的信息如“bus crash”,亦或是文章标题由于bucket限制被迫终止。