本文谈的是基于“Attention”的“Generation”,要展开这个话题,我们需要首先来谈谈何为“Genration”,以及何为“Attention”,最终定义什么是基于“Attention”的“Generation”。
什么是“Generation”呢?在我看来使用神经网络来生成的过程是这样的,神经网络按一个顺序一个一个地生成一个结构化的object。先用短语生成举例,短语是由一个一个词构成的,这样的句子具有一定的结构,那么用神经网络生成这样一个短语的过程就是按顺序生成一个个词向量的过程:
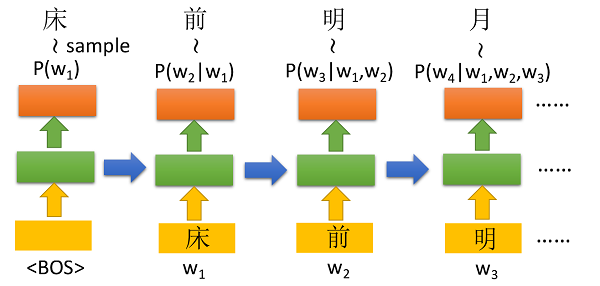
如图所示,首先输入的是
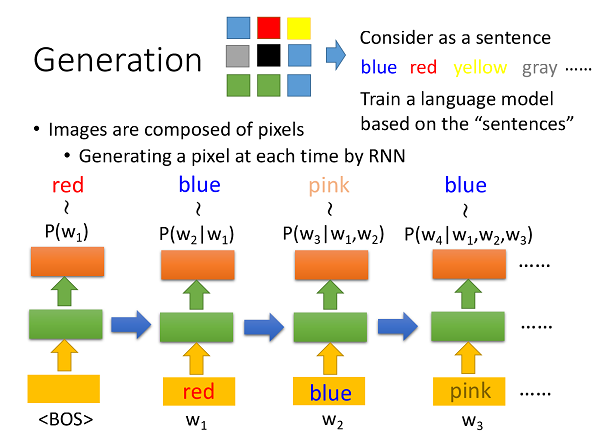
同样的过程也可以用来生成图片,和句子类似,图片也是由一个个component构成的,并且同样具有结构性,我们可以将图片的一个个pixel视作单词,这样就可以将生成句子的模型来直接生成图片:
我们可以将这种生成技术延伸至视频生成、手写字体生成(/机器作画)、以及声音信号的生成(使得机器人的声音听起来更像一个人)。
那么什么是Conditional Generation呢?上述的生成方法是完全有神经网络参数决定object生成方向的,也即生成的object并不具备某种具体的意义,仅仅是基于统计数据产生的。那么如何让NN产生有意义的object呢?这时就可以用到conditional generation了,比如把一幅图作为输入传入NN,那么NN可以生成一个sentence,这个sentence不再是随机生成的,它可能输出的是“新垣结衣在跳舞”这样有意义的话,这个过程正是基于我们输入图片这一个条件(condition)的;再比如,在和机器人聊天的过程中,我们希望机器人回答我们的话是对我们之前说过的话的一个回应,而不是答非所问,这就需要聊天机器人根据之前的condition来生成回答:

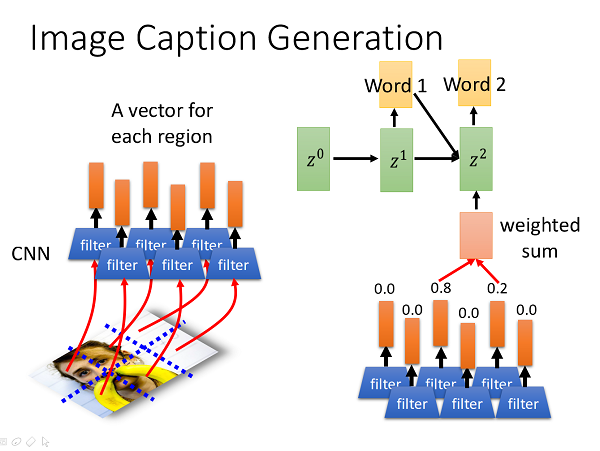
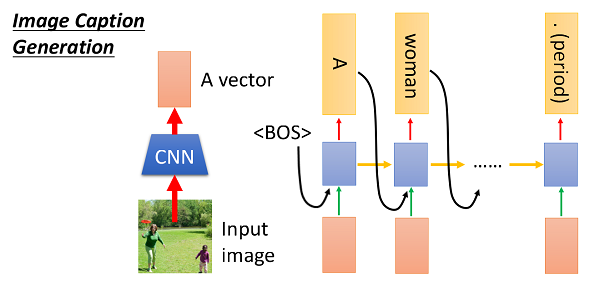
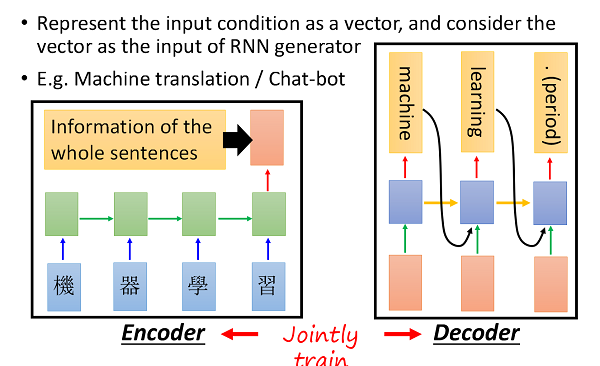
具体来说,我们可以把我们的condition以向量的形式作为RNN的输入,这样RNN生成的描述就是基于condition的了;对于图片,我们可以使用卷积神经网络来获得这张图片的向量形式的描述,然后将这个向量输入给后续的generative RNN,此即Image Caption:
在构造聊天机器人的过程之中,我们会对自然人的输入进行encoder,将用户输入自然语言编码成向量形式,该向量即包含了用户的语义,然后将该向量作为condition输入另一个RNN来生成应对的自然语言,而在训练的过程中,这两个RNN的参数是同时进行的;这种技术同样可以用到机器翻译上(我们有时也将这种训练技术称作encoder-decoder):
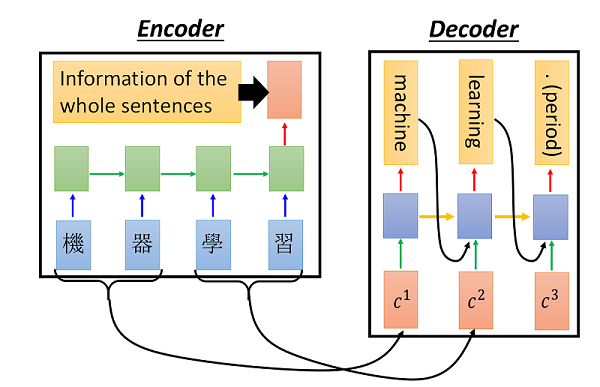
那么何为attention呢?顾名思义,attention意即我们并不关注全局信息,在生成局部信息时,我们只把我们的注意力放到condition中和当前要生成部位相关的部分,这是一种动态的生成方式,举个栗子,在进行机器翻译的时候,我们要翻译“机器学习”这个短语,那么我们在生成machine这个对应的单词时,更多考虑的则是原condition中的“机器”而并不在意“学习”。和原先的encoder-decoder相比,attention机制提供了更加强大的表达能力,在后一个RNN生成object的时候就更多地考虑结构上的信息。
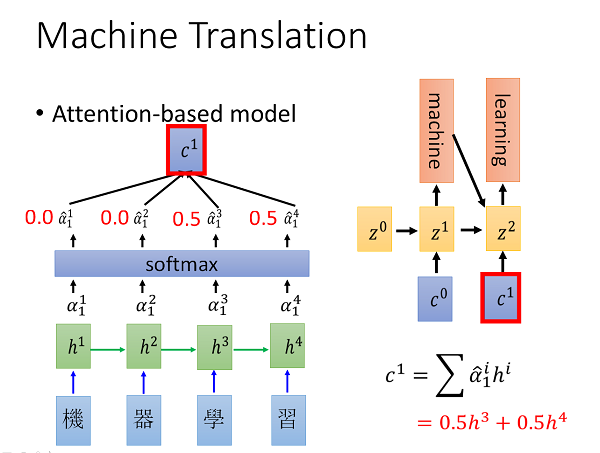
具体的做法则是这样的,对于将要翻译的句子,首先会将句子中的每个character都输入RNN并得到对应的输出值h1,h2,h3,h4,同时我们再定义多个数量和输出单词个数相同的向量z0,z1以及一个match函数,对于每一个变量z而言,我们都会计算每个隐层输出在当前z值的权重,计算的方法多种多样,可以是h和z的cos相似度;也可以是一个NN,这个NN的输入是h和z concat之后的新的向量,这个NN的参数会合另外两个RNN同时训练;也可以是transpose(h)Wz,最终得到一个scalar。在得到h1,h2,h3,h4在每个输出时刻对应的权重之后,会对他们进行softmax归一化,最后就可以计算每个输出时刻输出RNN的condition了,此时 c_time = sigma(alpha_i_time*hi_time)。那么此时的输入则是带有attention的condition了。
这种技术有如何应用到Image Caption上呢?我们会对图片的不同region进行卷积,从而得到多个局部描述向量,在不同的输出时刻这些向量有不同的权重组,对这些向量进行加权求和得到当前输出时刻的condition进而生成带attention机制的image caption。